

[주의] 개인 공부를 위해 쓴 글이기 때문에 주관적인 내용은 물론, 쓰여진 정보가 틀린 것일 수도 있습니다!
피드백 부탁드립니다. (- -)(_ _) 꾸벅
https://arxiv.org/abs/2011.06372
R-TOD: Real-Time Object Detector with Minimized End-to-End Delay for Autonomous Driving
For realizing safe autonomous driving, the end-to-end delays of real-time object detection systems should be thoroughly analyzed and minimized. However, despite recent development of neural networks with minimized inference delays, surprisingly little atte
arxiv.org
[전반적인 처리 흐름]

- Camera subsystem : Capture 이후 Queue 되기까지의 delay, Queue의 Arrival interval을 확률분포 A로 정의
- Detector subsystem : Queue에서부터 온 이미지가 detect되어 Display 되기까지의 delay, Queue의 Service interval을 확률분포 S로 정의
- Queue : Stack size Q에 대해 주어진 A와 S의 차이로부터 생기는 delay
저번 글에서 전반적인 처리의 흐름은 다음과 같다고 하였다. 첫번째로 Camera subsystem에서의 delay를 분석하였는데, 사실 실시간 시스템 처리에서의 나의 관심분야가 아니기 때문에 그냥 간략히 읽고 넘어갔다.
[1. Camera subsystem]

영상 frame은 비압축 픽셀 형식으로 가정하여 P라는 bpp을 가짐
따라서 이미지 frame 크기는


U=125us microframe 길이동안 사용할 수 있는 bandwidth는 B로 나타냄
따라서 transfer delay는

j (jitter)는 캡쳐 후 다음 microframe의 시작을 기다리고(최악일 경우 U), URB가 그룹화되기를 기다리며(최악일 경우 (M-1)*U) 생기는 delay. 그러므로 j의 범위는

Transfer delay는 URB buffering period의 배수로 결정된다. 이미지 도착 간격이 URB 버퍼링 기간 (M · U)의 배수이기 때문에 A는 (보통) 두 값 amin 및 amax를 갖는 이산 확률 분포이게 된다.

[2. Detector Subsystem]
1. Fetch
V4L2는 스트리밍 I/O 방식이므로 실제 메모리 복사가 없다. 대부분의 실행시간은 DNN 입력 Layer와 해상도를 일치시킬 때 필요한 Resizing에서 소요된다고 한다. 입력해상도(rin)와 출력해상도(rout)의 함수인 확률분포인 Dfetch를 따르게 된다.


입력해상도 및 출력해상도가 낮을 수록 확률적으로 더 낮은 delay가 발생한다.
이제 fetch 모듈의 delay인 dfetch를 release(fetch thread 시작)와 completion(이미지 resize 완료) 사이의 시간으로 일반화 할 수 있다.
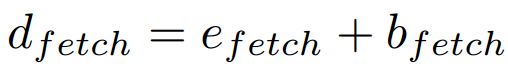
Bfetch는 blocking time factor이다. Queue가 비어 있는 동안 fetch 모듈이 이미지를 fetch하려고 하면, Queue에 새로운 이미지가 도착할 때까지 차단하기 위한 요소.

2. Inference
CPU와 GPU파트를 분해하여 neural network를 forward propagation한다. CPU 스레드는 CUDA 동기화 함수를 명시적으로 호출하여 비동기 GPU 작업이 완료될 때까지 차단한다. Inference 모듈의 실행시간은 신경망의 입력인 rnn의 해상도에 따라 다르다, 그러므로 Inference 모듈에서 CPU실행시간과 GPU실행시간은 다음과 같다.


해상도가 낮을 수록 더 적은 추론 시간을 갖는다.
표기의 편의상을 위해

Inference 모듈의 delay는 아래와 같이 쓸 수 있다.
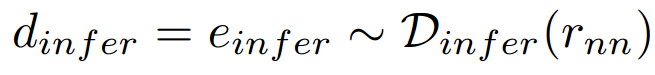

실행시간의 대부분을 GPU part였다.
3. Display
탐지결과를 bounding box를 그려 visualize해주는 단계이다.
세가지 step을 따름
- 다양한 confidence 수준을 가진 detection 결과를 threshold의해 필터링
- 겹쳐져 있는 bound box를 non-maximal suppression 알고리즘으로 삭제
- 각각의 detected object 좌표에 rectangle을 그림
Display의 실행시간은 detection object 수에 관련 있다.

Display에 이미지를 렌더링하기 위해 OpenCV 함수를 호출하는 과정에서 생기는 Blocking factor인 bdisp 존재한다.
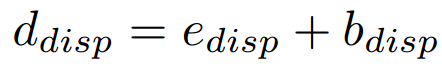
최악의 경우, 감지 가능한 최대 개체 수인 obj=30 에 대한 프로파일링 결과는 아래와 같다.

[Multithreaded pipeline architecture]

Multi core processor를 활용하기 위해 사용되는 파이프라인 아키텍처 (fork-join model)이다. Fetch Thread, Inference Thread, display Thread 세 종류로 구성되어 있다. 보통 Inference 주기가 길기 때문에 다른 스레드는 Inference 주기가 끝날 때 까지 기다려야 한다! 일반적으로 표현하면 아래와 같음

따라서 한 감지 주기는 다음과 같다. two object detection cycles plus one delay of the display thread
