[주의] 개인 공부를 위해 쓴 글이기 때문에 주관적인 내용은 물론, 쓰여진 정보가 틀린 것일 수도 있습니다!
피드백 부탁드립니다. (- -)(_ _) 꾸벅
µLayer: Low latency on-device inference using cooperative single-layer acceleration and processor-friendly quantization
Emerging mobile services heavily utilize Neural Networks (NNs) to improve user experiences. Such NN-assisted services depend on fast NN execution for high responsiveness, demanding mobile devices to minimize the NN execution latency by efficiently utilizin
yonsei.pure.elsevier.com

[ 1. Introduction ]






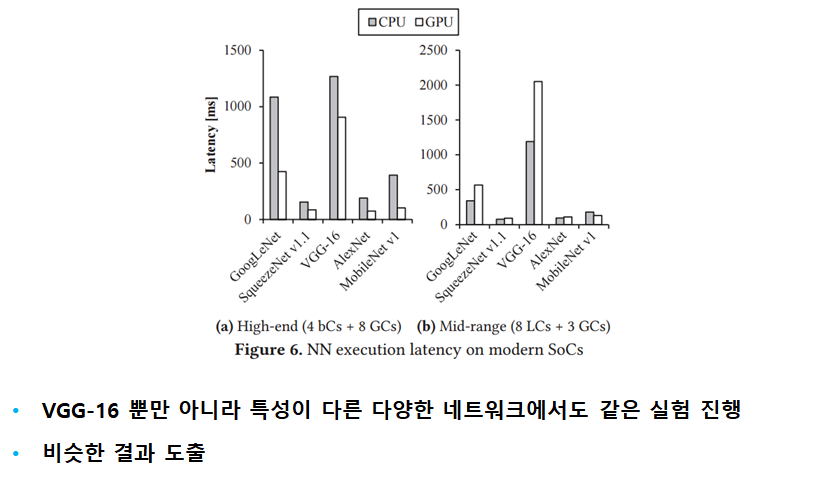
[ 2. BackGround ]



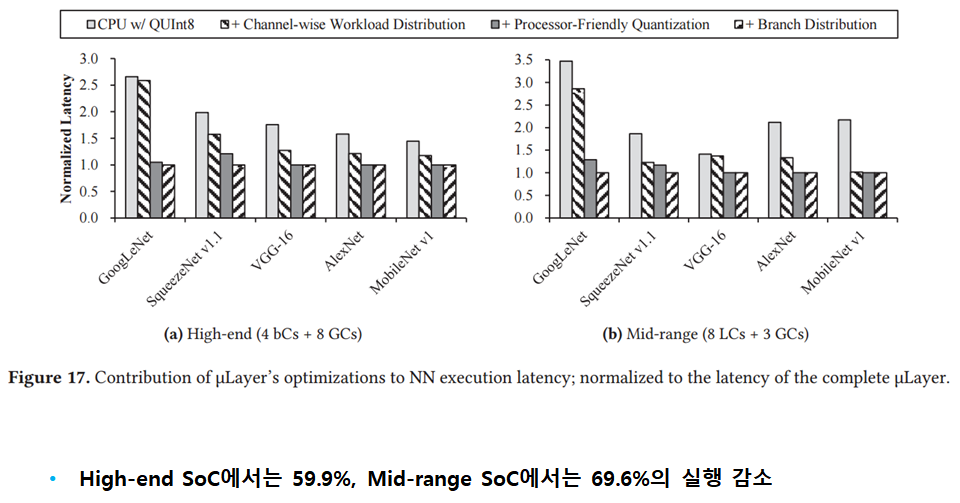
[ 3. Cooperative Single-Layer Acceleration ]



[ 4. Processor-Friendly Quantization ]


[ 5. Branch Distribution ]


[ 6. Implementation ]


[ 7. Experiment ]